脸书开源自家视讯装置Portal、Messenger个人助理M使用的自然语言处理开发框架PyText
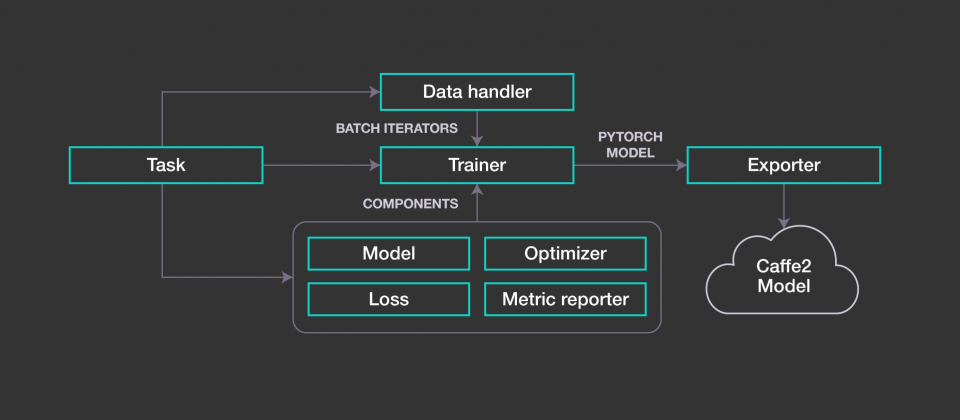
为了加速建构与部署自然语言处理系统,脸书开源了PyText,这是建构于开源深度学习框架PyTorch之上的函式库,不只能模糊实验和大规模部署阶段,简化工作流程更快速进行实验,同时还能存取预先建置的模型基础架构,以及文字处理和词彙管理工具,帮助大规模部署。
脸书使用自然语言处理技术,向使用者提供相关的语言辅助功能、标记违反政策贴文以及进行翻译。由于对话式人工智慧技术发展快速,脸书以PyText来快速推进这些应用提高服务品质,PyText现在还被用于脸书新的影像通话装置Portal和Messenger中的M建议功能。
透过使用PyText,Portal中支援Hey Portal的组合与嵌套呼叫查询的语音命令,该功能允许使用者以语音命令,进行诸如打电话等动作,脸书举例,使用者可以使用「打电话给我爸爸」这样的语句,而这需要系统了解呼叫者与被呼叫者的关係,PyText的工作之一便是能进行语义分析,并快速的将该技术应用到产品。
脸书利用PyText快速迭代的方式,渐进改进Portal的自然语言处理模型,包括加入组合演算法、条件随机域以及合併模型等技术。这样的方法让其核心领域的模型精确度提高5%到10%,并且也因为PyText支援分散式训练,让Portal模型的训练时间缩短了3到5倍。
PyText快速迭代不只能以渐进的方式改进模型,还可以提高自然语言处理模型的效率和可扩展性,无论是在Portal或是Messenger等其他应用,脸书都需要能即时的执行模型并且做出回应,并且能够大规模高效能执行的自然语言处理系统,PyText现还为脸书数十亿人存在多语言的社交平台,提供进阶即时的自然语言处理功能。
PyText能利用脸书的其他自然语言系统为基础,补充其功能上的不足,像是工程师可以使用fastText函式库训练单词嵌入,并在PyText中使用。另外,PyText改进了脸书现有文字理解引擎DeepText的缺点,并得利于GPU还有分散式训练技术,PyText加速了整体训练过程。由于模型中的条件执行和自定义资料结构,导致PyText无法与DeepText在部分语意解析和多任务学习模型等工作合作,脸书正计画让PyText作为主要的自然语言平台,以增加系统未来的发展性。
PyText建构于PyTorch之上,并且和ONNX与Caffe2互通,工程师可以将PyTorch模型转换成ONNX,并以Caffe2输出,作为大规模生产部署之用。PyText提供灵活模组化的工作流程,模型元件具有可配置的系统层与可扩展的介面,可作为端到端平台,供开发人员开箱即用,创建完整自然语言处理工作管线。

其模组化的结构,允许工程师将各个元件整合到现有的系统中,每个元件的角色和与其他模组的交互作用,皆取决于特定的任务。这种模组化的设计方法增强了PyText的多功能性,几乎可以在研究到生产的过程任一阶段使用,无论是要从头建构整个自然语言处理系统,抑或是对现有系统进行修改都可以。
PyText框架支援分散式训练,以及可以同时训练多个模型的多任务学习功能。由于 PyText模型建构在PyTorch之上,具高可移植性,可以在不同平台间转换,而且透过预建置的模型,例如文字分类,单词标记、语意分析和语言建模,PyText可以简单地在新的资料上使用预建模型。
为了最佳化产品阶段的推理,PyText使用PyTorch 1.0的功能,输出经过最佳化的Caffe2模型。原生PyTorch模型需要Python Runtime,但由于Python全局解释器锁(Global Interpreter Lock,GIL)多执行绪的限制,导致模型无法有效的扩展,但PyText使用者可以选择输出为Caffe2模型,就能利用高效能多执行绪C++后端,处理高吞吐流量。
经过内部部署后,脸书提到,PyText确实能够快速迭代工程师的对自然语言建模想法,并将其框展至生产当中,PyText现为脸书提供每日超过10亿次的推理。未来还会提供多语言建模和其他建模工具,让模型更容易侦错,并为分散式训练进行最佳化,脸书也提到,目前要在行动装置上部署複杂的自然语言处理模型仍然很具挑战性,但他们仍朝向在装置上建构端到端工作流程的方向努力。
免责声明:本文由用户上传,如有侵权请联系删除!
猜你喜欢
最新文章
- 个性标签写什么好8个字(个性标签8个字简介介绍)
- 贴吧和i吧有什么区别(贴吧和i吧有什么区别)
- 东北话得细小是什么意思(东北话小得得是啥意思)
- 太姥山旅游最新攻略一日游(太姥山旅游线路)
- 12月有什么好电影上映(12月上映好看的电影)
- 妒海主题曲百度云(泰剧妒海的主题曲和片尾mp3格式的谁有谢谢)
- 元奎在好莱坞拍过多少电影(指导过多少电影 都叫什么)
- 怎么关闭wps删除提示(wps屏幕提醒怎么关闭简介介绍)
- 4399弹弹堂vip折扣券(4399弹弹堂怎么刷点券啊)
- 企业天猫入驻条件及费用(天猫入驻条件及费用简介介绍)
- 尹相杰母亲是马玉涛吗(尹相杰母亲是马玉涛吗)
- 冬至应该吃什么食物(冬至应该吃什么食物)
- nokia6600复刻版本(NOKIA6630~~~)
- 新年快乐日语怎么说(新年快乐日语怎么说)
- 工作交接清单怎样写,格式是怎样的(工作交接清单怎样写格式是怎样的简介介绍)
- 为什么我的梦幻诛仙人物快捷键用不出来(求高手解答 我换了很多台机子了)
- 三星note3开不了机(三星note1手机为什么开不了机)
- 迅雷种子怎么提取(前缀是什么)
- poison(ivy 什么意思)
- 魔法卡片掉卡规则(魔法卡片中怎么没有变闪卡的卡友)
- 眼部结构简图(眼部结构简介介绍)
- 武汉外高国际部学费(武汉外高出国)
- 湖南台为什么叫马桶(湖南台为什么叫芒果台)
- 公元前10000年是什么年(公元前10000年)