NVIDIA Ampere A100 GPU打破16项AI世界纪录 比Volta V100快4.2倍
NVIDIA刚刚发布了其Ampere A100 GPU的第一个实际性能数据,结果让人抓狂。该公司在特定AI基准测试中总共打破了16项性能记录,并在特定机器学习性能类别中击败了主要竞争对手,获得了巨大的领先优势。

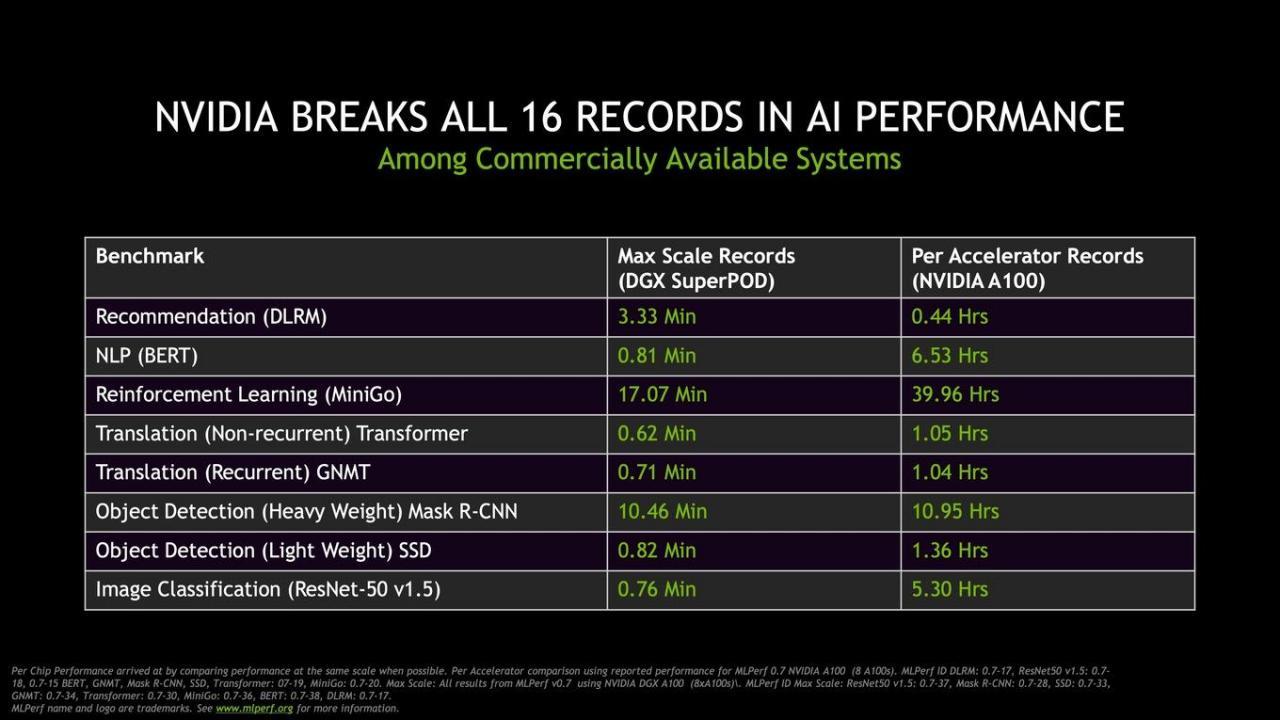
来自MLPerf的结果。MLPerf是2018年成立的行业基准测试小组,专注于机器学习性能。基准测试包共包括8项测试,NVIDIA以创纪录的训练速度发布了所有记录。
这是英伟达连续第三次在2018年5月成立的行业标杆机构MLPerf进行培训测试,也是表现最强的一次。NVIDIA在2018年12月的第一次MLPerf培训基准测试中创造了6项记录,在2019年7月创造了8项记录。
英伟达是唯一一家为所有测试提供商业产品的公司。提交使用的大多数其他预览类别是可能在几个月内不可用的产品,而研究类别使用预计时间内不可用的产品。
英伟达博客
英伟达还报告了其DGX superpad系统的八项新记录,该系统是由HDR InfiniBand连接在一起的DGX A100高性能计算系统的巨大集群。一个DGX superpad由140个DGX A100系统组成,共有1,120个NVIDIA Ampere A100 GPU、170个Mellanox Quantum 200G Infiniband交换机、4 PB存储空间和15公里光缆。
在令人惊叹的DGX superpad系统中,大约有770万安培的CUDA内核。该系统是DGX五号扩展计划的一部分,该计划为该系统增加了近700千兆次的计算能力。该系统已在位于加州圣克拉拉的英伟达总部部署。
人工智能性能基准-安培vs伏特更多。
英伟达已经将其安培A100 Tensor Core GPU加速器与其前身Volta V100进行了比较。对比还包括谷歌的第三代TPU和华为的Ascend HPC芯片。MLPerf本身列出了更详细的基准,并预览了即将推出的AI加速器,例如英特尔的Cooper Lake-SP至强CPU和谷歌的第四代TPU。说到这里,让我们看看基准测试本身。
根据MLPerf的说法,他们的基准测试套件包括机器学习和人工智能类别中最相关的性能工作负载测试。NVIDIA Ampere A100只摧毁了Volta V100,但性能提升了2.5倍。即使领先优势最低,Ampele A100仍比Volta V100 GPU高出50%,令人印象深刻。在这里,芯片规模已经标准化为单个GPU,从而对Ampere和Volta进行合理的对比。
华为的Ascend芯片只能及时完成一次测试,性能比Volta V100差,而谷歌的TPU V3只能及时完成两次测试。在一次测试中,该芯片领先NVIDIA Volta V100 20%,而在第二次测试中,它比v 100慢10%。
对比库柏莱克-SP 8插槽配置,可在1104.53分钟内完成图像分类测试,双NVIDIA A100系统仅需33.37分钟即可完成同样的测试。英伟达还继续将安培A100的性能与尚未发布的谷歌TPU V4进行比较。谷歌TPU V4仍处于研究阶段,距离上市至少还有一年时间。
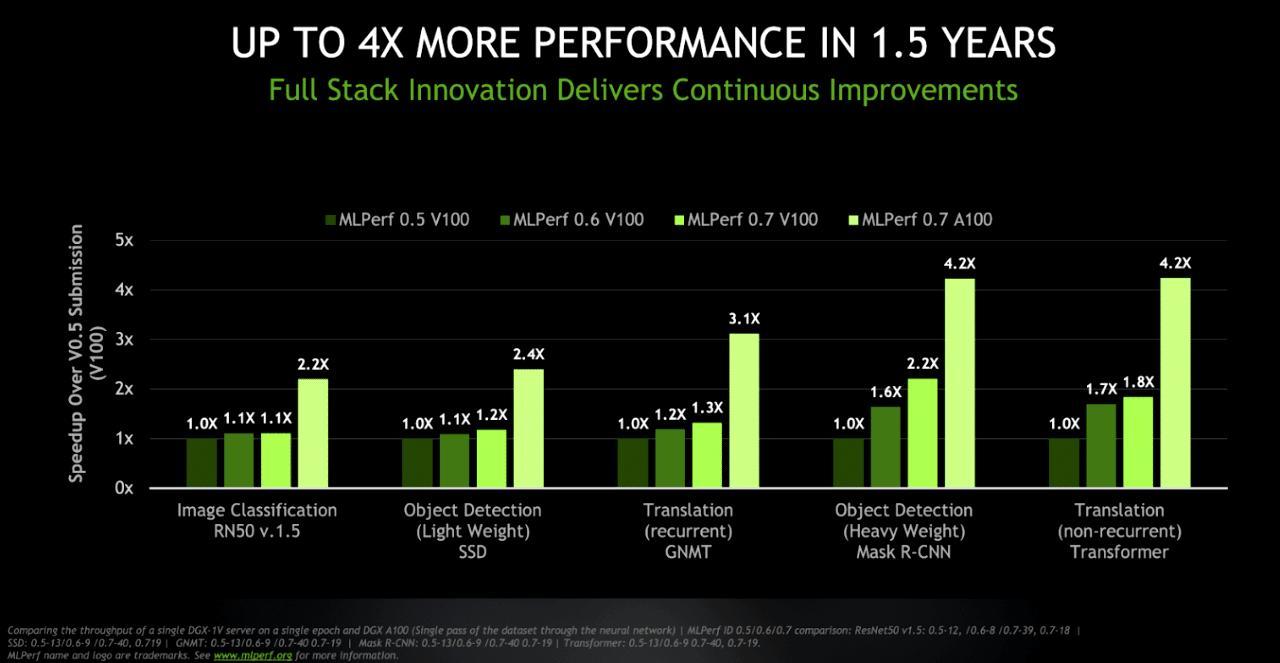
NVIDIA还展示了其GPU加速器的性能如何随着AI的最新全堆栈创新而不断提升。与在Volta V100上运行的MLPerf 0.5相比,与Ampere A100一起运行的MLPerf 0.7套件提供了惊人的4.2倍性能提升。
这证明了NVIDIA Ampere A100 GPU的芯片在AI界各大玩家公认的套件真实标杆中是令人印象深刻的。即使与图灵GPU相比,Ampele A100 GPU也被认为是另一项基准测试中速度最快的GPU。图灵GPU的硬件加速技术可以提供更好的性能,但仍然无法与Ampere A100及其强大的性能输出相提并论。所有这些基准函数都让我们更乐意看到安培以消费者的形式出现,这肯定会在几个月后发生。
免责声明:本文由用户上传,如有侵权请联系删除!
猜你喜欢
最新文章
- 个性标签写什么好8个字(个性标签8个字简介介绍)
- 贴吧和i吧有什么区别(贴吧和i吧有什么区别)
- 东北话得细小是什么意思(东北话小得得是啥意思)
- 太姥山旅游最新攻略一日游(太姥山旅游线路)
- 12月有什么好电影上映(12月上映好看的电影)
- 妒海主题曲百度云(泰剧妒海的主题曲和片尾mp3格式的谁有谢谢)
- 元奎在好莱坞拍过多少电影(指导过多少电影 都叫什么)
- 怎么关闭wps删除提示(wps屏幕提醒怎么关闭简介介绍)
- 4399弹弹堂vip折扣券(4399弹弹堂怎么刷点券啊)
- 企业天猫入驻条件及费用(天猫入驻条件及费用简介介绍)
- 尹相杰母亲是马玉涛吗(尹相杰母亲是马玉涛吗)
- 冬至应该吃什么食物(冬至应该吃什么食物)
- nokia6600复刻版本(NOKIA6630~~~)
- 新年快乐日语怎么说(新年快乐日语怎么说)
- 工作交接清单怎样写,格式是怎样的(工作交接清单怎样写格式是怎样的简介介绍)
- 为什么我的梦幻诛仙人物快捷键用不出来(求高手解答 我换了很多台机子了)
- 三星note3开不了机(三星note1手机为什么开不了机)
- 迅雷种子怎么提取(前缀是什么)
- poison(ivy 什么意思)
- 魔法卡片掉卡规则(魔法卡片中怎么没有变闪卡的卡友)
- 眼部结构简图(眼部结构简介介绍)
- 武汉外高国际部学费(武汉外高出国)
- 湖南台为什么叫马桶(湖南台为什么叫芒果台)
- 公元前10000年是什么年(公元前10000年)