为了推广AI 研究人员用电脑玩老式的文字冒险游戏
长期以来,游戏一直被用作人工智能的测试平台和标杆。最近几个月,成绩有很多不足。谷歌的DeepMind的AlphaGo和卡内基梅隆大学的扑克机器人天平动(天平动)都在传统上对AI来说很难的游戏中击败了人类专家——大约20年前,IBM的DeepBlue在国际象棋上取得了同样的成就。
这样的游戏有明确规定的规则的吸引力。对于人工智能研究人员来说,它们相对简单和便宜,并且以任何期望的难度提供各种认知挑战。通过发明可以工作的算法,研究人员希望对自动操作所需的机制有深入的了解。
随着AI和机器学习最新技术的到来,人们的注意力现在已经转移到视觉细节的电脑游戏上,包括3d射击游戏《毁灭战士》(Doom)、各种2d雅达利游戏(如Pong和Space intruss)和实时策略。游戏《星际争霸》。
这当然都是进步,但更大的AI画面的关键部分被忽略了。这项研究优先考虑游戏,在游戏中,所有可以执行的动作,无论是移动骑士还是发射武器,都是预先知道的。从一开始就为计算机提供了所有选项,重点是它们之间的选择程度。问题是,这使得人工智能研究偏离了让计算机真正自主的任务。
香蕉皮
迄今为止,游戏研究人员几乎没有试图解决让计算机决定甚至存在于给定环境中的动作的概念和实际挑战。猴子和香蕉问题是长期以来人工智能问题的一个例子,最近没有任何进展。
这个问题最早是由AI创始人之一的约翰麦卡锡在1963年提出的:一个房间的天花板上挂着一把椅子、一根棍子、一只猴子和一串香蕉。任务是让电脑提出一系列动作,这样猴子就能得到香蕉。
麦卡锡从人工智能的角度区分了这项任务的两个方面。物理可行性确定一个特定的动作序列在物理上是否可以实现;以及与认识论或知识相关的可行性——决定猴子实际可能采取的行动。
如果所有可能的动作——“爬上椅子”、“挥动棍子”等。都是提前通知的,计算机很容易确定对猴子来说物理上可行的方法。一个简单的程序指示计算机一个接一个地执行所有可能的操作序列,很快就会得到最佳解。
然而,如果计算机必须首先确定它甚至可以执行什么操作,它将面临更大的挑战。它提出了关于我们如何表达知识,知道某事的必要和充分条件,以及我们如何知道何时获得足够的知识的问题。在强调这些问题时,麦卡锡说:“我们的最终目标是让程序像人类一样有效地学习经验。”
除非计算机在没有任何可能操作的预先描述的情况下解决问题,否则这个目标无法实现。遗憾的是,AI研究人员忽略了这一点:这些问题不仅变得更加困难和有趣,而且似乎也是在这一领域取得更有意义进展的前提。
书面上诉
为了在复杂的环境中自主操作,不可能事先描述如何最好地操纵甚至表征那里的物体。教计算机克服这些困难会立即引发关于从以前的经验中学习的深刻问题。
与其专注于像《毁灭战士》或《星际争霸》这样可以避免这个问题的游戏,不如更有希望地测试现代AI,这可能是上世纪七八十年代微不足道的文字冒险。
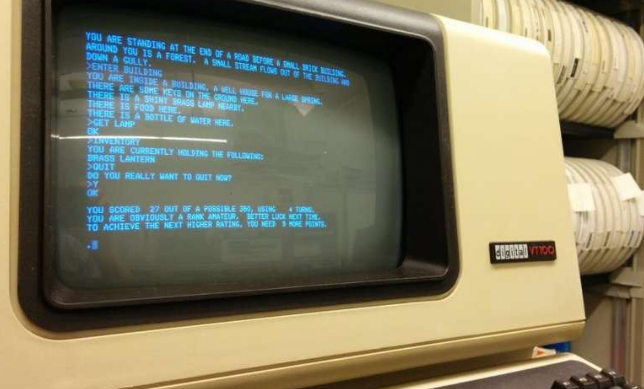
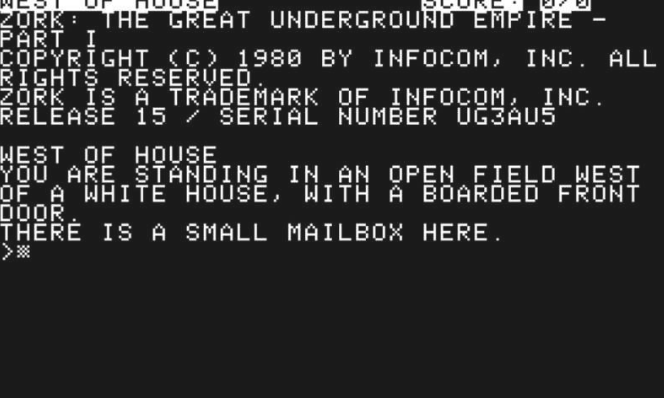
在计算机还没有复杂的图形功能的时候,像“巨大洞穴”和“佐克”这样的游戏非常流行。屏幕上的信息告诉玩家他们所处的环境:
他们必须用简单的指示来回应,通常是动词或动词加名词的形式——“看”、“拿盒子”等。挑战的一部分是找出哪些行动是可能的和有用的,并做出相应的反应。
对于现代AI来说,一个很好的挑战就是在这样的冒险中扮演玩家的角色。计算机将必须理解屏幕上的文本描述,使用某种预测机制来确定它们可能产生的影响,并通过行动做出反应。
计算机上更复杂的行为包括探索环境、定义目标、做出面向目标的行动选择以及解决各种智力挑战。
由IBM、谷歌、脸书或微软等科技巨头推动的现代人工智能方法在这些文字冒险中表现如何,这是一个悬而未决的问题——它们在每个新场景中将需要多少专业的人类知识。

为了衡量这一领域的进展,在过去两年中,我们一直在参加今年8月在荷兰马斯特里赫特举行的IEEE计算智能和游戏会议。参与者需要提前提交自己的参赛作品,他们可以通过理解文本描述并输出适当的文本命令,使用自己的AI技术构建程序来玩这些游戏。
简而言之,如果人工智能要继续改进,研究人员需要重新考虑他们的优先事项。如果我们发现这个学科被忽视的根是有成果的,猴子可能最终会得到他的香蕉。
免责声明:本文为转载,非本网原创内容,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
最新文章
- DNF搬砖最佳宠物搭配指南
- DNF白金徽章变现攻略:如何巧妙出售白金徽章
- 寒潮蓝色预警:近两日最低气温 0℃线南压至江南南部至贵州南部和云南北部一带
- DNA 纳米机器人:可改造人造细胞,推动合成生物学发展
- 新型巨型里德伯原子成为精准量子温度计
- 《生化危机9》重大爆料:里昂确定回归主角,吉尔缺席引热议
- 广东:到 2027 年 绿色低碳循环经济体系基本建成
- 2024 财年美国对外军售额创历史新高:背后的战略与影响
- 离子阱量子计算在近年实现双码纠错
- 这次与肯德基的全新联动,星铁再次硬控玩家热情?
- 新年多城土地市场回温:杭州单价地王纪录 3 个月内两度被打破,民企恢复拿地
- 扎克·克雷格执导新版《生化危机》电影,发行权引多家大公司激烈争夺
- 广东:积极推进煤炭消费控制,全力构建以新能源为主体的新型电力系统
- 广东:到 2027 年,全力构建绿色低碳循环经济体系
- 长三角铁路春运再创佳绩:昨日发送旅客 310.2 万人次
- 海通策略:2025 年政策见效下市场望步入基本面驱动新阶段,结构上科技制造确定性更强
- 《最终幻想14》水晶世界青魔法师职业任务全攻略
- 上海:推出乡村振兴领域优秀博士后创新计划,打造高潜力创新人才‘储备库’
- 春节机票价格跳水至百元,航司退差价政策各异引关注
- 浙江:到 2030 年,LNG 年接收能力达 4250 万吨
- 上海:启动乡村振兴博士后创新计划,打造高潜力人才‘蓄水池’
- 币界网晚讯速递:SHIB币价攀升至0.00002044美元,日内涨幅达2.10%
- 不知火舞《街霸6》惊艳换衣秀,细节之处尽显匠心,玩家为之痴狂
- 中国汽车:奋力争夺超豪华市场入场券