Cloud Dataproc现支援SparkR工作突破基础架构限制进行R大规模分析

GCP宣布在其Cloud Dataproc服务上释出SparkR作业的测试版,供资料科学家在需要扩展分析规模的时候,利用託管的运算资源。使用者可以选择使用云端伺服器版的RStudio,以获取备份与高效能执行的优点。
R语言通常用建构资料分析工具和统计应用程式,而SparkR是一个轻量级的前端套件,供开发者在Apache Spark上开发R语言应用,而这整合让R开发人员可以,使用类似dplyr的资料操作语法,操作储存在云端各种大小的资料集。SparkR还支援使用MLlib进行分散式机器学习,使用者可以用来处理大型云端储存资料及或是运算密集的工作。
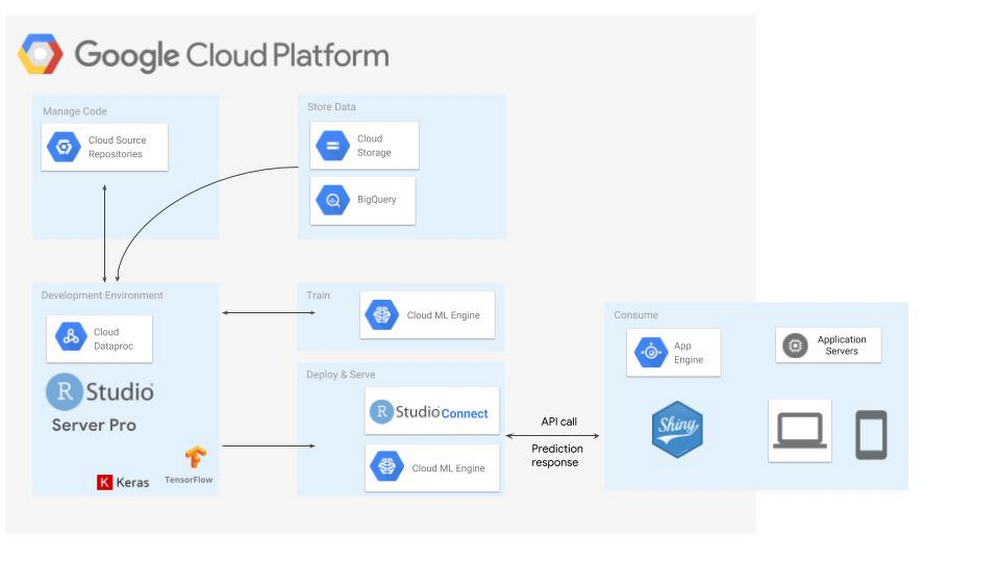
而Cloud Dataproc是GCP的完全託管云服务,使用者能以简单且高效能的方式执行Apache Spark和Apache Hadoop丛集。 Cloud Dataproc工作API可以轻鬆的将SparkR工作分派到丛集中,无需开放防火墙才能利用网页IDE或是SSH存取主结点,而且藉由工作API,可以自动重複在资料集上进行R统计。在GCP上使用R可以避免因为基础设施所带来分析上的限制,使用者可以自由建构大型模型,以分析过去需要高效能计算基础架构才能运算的资料集。
虽然SparkR工作API提供简单的方式,执行SparkR程式码并自动运行任务,但大多数R开发人员仍习惯使用RStudio进行探索性分析,而GCP上的R也提供开发人员熟悉的RStudio介面。而提供介面的RStudio伺服器可以在Cloud Dataproc主节点、Google Compute Engine虚拟机器,甚至是在GCP之外运行都可以。
开发者可以选择在GCP上创建RStudio伺服器,并在不需要的时候关闭,开发者还可以选择RStudio的商业发行版RStudio Pro。Google表示,虽然从桌面连接到云端是一种使用RStudio的方法,但大多数R开发人员仍喜欢使用云端伺服器版的RStudio,从任何工作地点获取桌面设定,在个人电脑之外备份工作,并将RStudio设置在与资料来源相同的网路中,利用Google的高效能网路可以大幅提高R应用的效能。
在Cloud Dataproc上执行RStudio的另一个优点,是开发者可以利用Cloud Dataproc自动扩展功能(Autoscaling),在开发SparkR逻辑时可以使用最小丛集规模,一旦工作需要大规模处理时,开发者不需要修改伺服器,只要将SparkR工作提交给RStudio,Dataproc丛集便会根据设定的区间,自动扩展以满足工作需要。
GCP上的运算引擎能良好的扩展R的统计功能,透过BigQuery套件包,开发者能查询BigQuery表格并检索相关专案的元资料、资料集、表格和工作。在Cloud Dataproc上执行SparkR套件时,可以使用R来分析和建构储存在云端中的资料。
一旦探索完毕,準备进入建模阶段,开发者可以使用TensorFlow、Keras和Spark MLlib函式库,TensorFlow存在R介面能够利用进阶Keras和Estimator API,而需要更多控制时,开发者也能拥有完全存取核心TensorFlow API的权限。Dataproc上的SparkR工作允许开发者大规模训练和评分Spark MLlib模型。另外,想要大规模训练和託管TensorFlow和Keras模型时,也可以使用R介面存取云端机器学习引擎,直接让GCP代为管理资源。
免责声明:本文为转载,非本网原创内容,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
猜你喜欢
最新文章
- DNF搬砖最佳宠物搭配指南
- DNF白金徽章变现攻略:如何巧妙出售白金徽章
- 寒潮蓝色预警:近两日最低气温 0℃线南压至江南南部至贵州南部和云南北部一带
- DNA 纳米机器人:可改造人造细胞,推动合成生物学发展
- 新型巨型里德伯原子成为精准量子温度计
- 《生化危机9》重大爆料:里昂确定回归主角,吉尔缺席引热议
- 广东:到 2027 年 绿色低碳循环经济体系基本建成
- 2024 财年美国对外军售额创历史新高:背后的战略与影响
- 离子阱量子计算在近年实现双码纠错
- 这次与肯德基的全新联动,星铁再次硬控玩家热情?
- 新年多城土地市场回温:杭州单价地王纪录 3 个月内两度被打破,民企恢复拿地
- 扎克·克雷格执导新版《生化危机》电影,发行权引多家大公司激烈争夺
- 广东:积极推进煤炭消费控制,全力构建以新能源为主体的新型电力系统
- 广东:到 2027 年,全力构建绿色低碳循环经济体系
- 长三角铁路春运再创佳绩:昨日发送旅客 310.2 万人次
- 海通策略:2025 年政策见效下市场望步入基本面驱动新阶段,结构上科技制造确定性更强
- 《最终幻想14》水晶世界青魔法师职业任务全攻略
- 上海:推出乡村振兴领域优秀博士后创新计划,打造高潜力创新人才‘储备库’
- 春节机票价格跳水至百元,航司退差价政策各异引关注
- 浙江:到 2030 年,LNG 年接收能力达 4250 万吨
- 上海:启动乡村振兴博士后创新计划,打造高潜力人才‘蓄水池’
- 币界网晚讯速递:SHIB币价攀升至0.00002044美元,日内涨幅达2.10%
- 不知火舞《街霸6》惊艳换衣秀,细节之处尽显匠心,玩家为之痴狂
- 中国汽车:奋力争夺超豪华市场入场券